

The Trojan Source Attack, tracked as CVE-2021-42574, and disclosed on , works by using invisible unicode characters used to control interpretation of text as left-to-right or right-to-left to craft malicious source code which appears to function in one way, but is compiled in another. Code which seems to be valid could be commented out.

Figures 3 and 4 from “Trojan Source: Invisible Vulnerabilities” by Nicholas Boucher and Ross Anderson
Atlassian has updated Bitbucket to highlight these characters in pull requests and source code view to make it more obvious when one of these characters has been inserted into your source code: Multiple Products Security Advisory - Unrendered unicode bidirectional override characters - CVE-2021-42574.
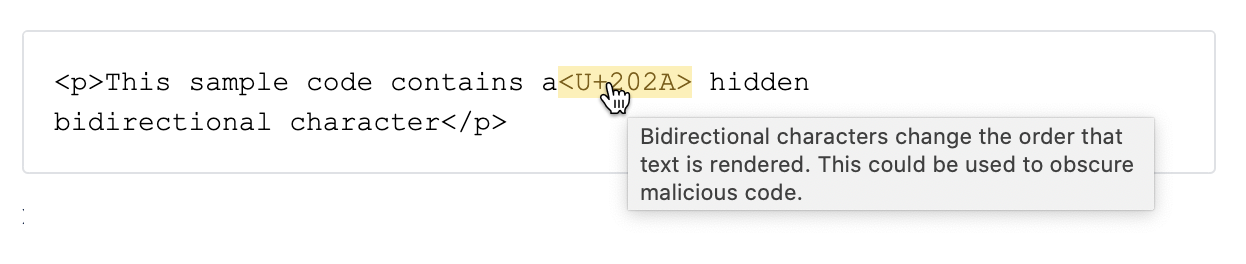
Bitbucket’s mitigation for Trojan Source attacks highlights the hidden characters for reviewers.
But what if you want to prevent these characters from being committed, or automatically audit your Bitbucket instance for this attack? Security for Bitbucket offers a built-in rule to find and block these potential attacks.
-
Install Security for Bitbucket 3.8.0 or greater – this is the first version with the
TROJAN_SOURCErule. It is enabled by default. Version 3.9.0 or greater also displays unicode bidirectional override characters in the Security Scan Report. -
Run a total instance re-scan, using the
forceparameter to re-scan already scanned code with this new rule. See REST API for Mass Scanning. -
Turn on the Security Hook included with Security for Bitbucket to prevent new potential malicious code from being committed. See Scanning Every Push with the Soteri - Scan Commits Security Hook for more information.
-
Update your Bitbucket version as recommended by Atlassian to allow for reviewers to see these characters in code reviews.
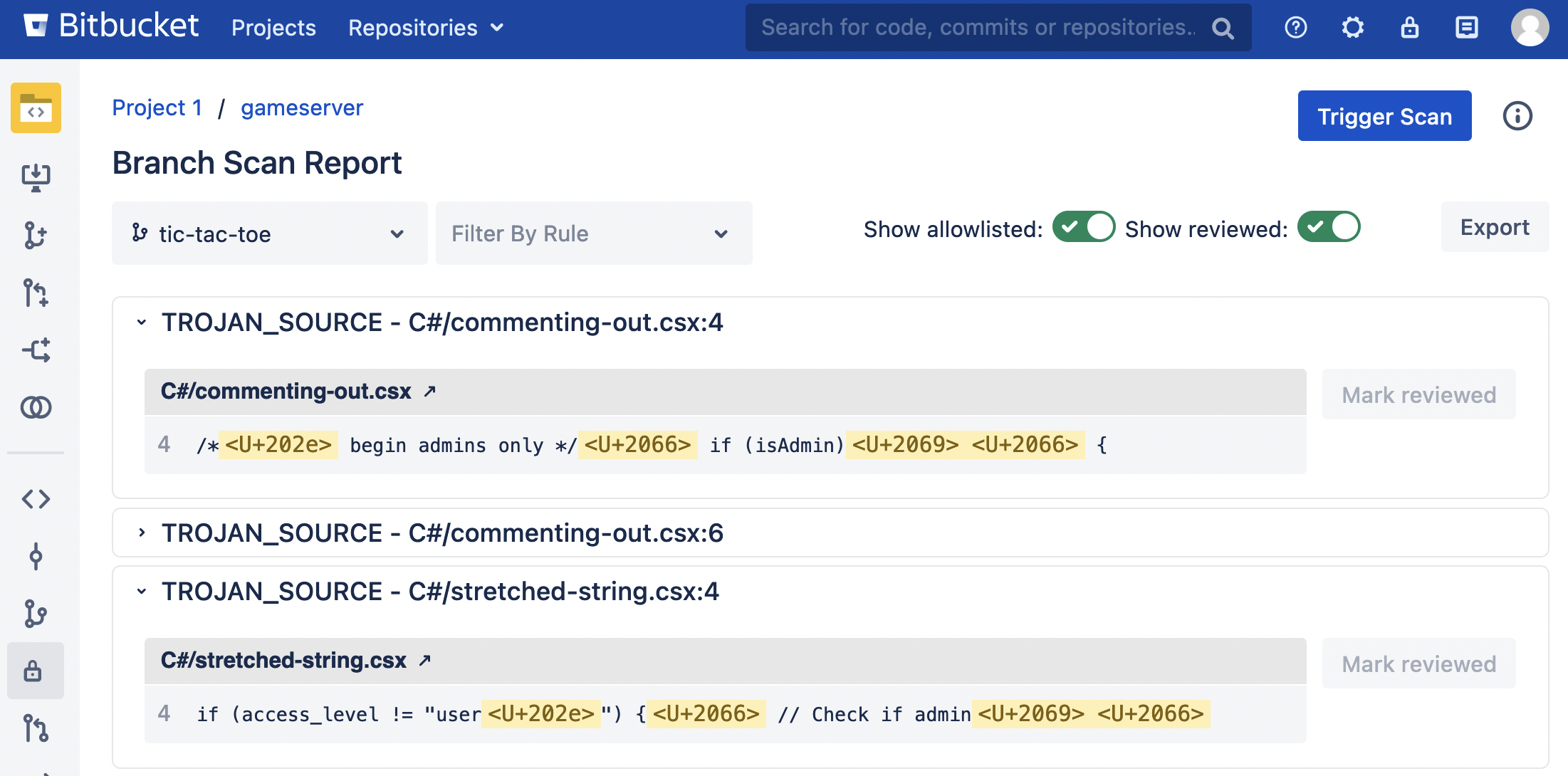
Displayed bidirectional override characters in the Security Scan Report
For more information on the vulnerability, you can visit Trojan Source Attacks and read the paper.
What about homoglyph attacks?
The TROJAN_SOURCE rule does not attempt to the homoglyph attack described in the Trojan Source paper, as such a rule generates a lot of false positives on non-English content.
If you’re interested in creating a custom rule which detects homoglyphs, there’s two approaches to crafting such a rule.
First, the Unicode Consortium maintains a list of “confusables” - characters which could be used malicious source code attempting a homoglyph attack, here: Unicode confusables.txt. A custom rule could be crafted to detect all confusables which are relevant to your code base.
Second, the Unicode Consortium also maintains a list of character blocks here: Unicode Blocks.txt. Characters in these blocks can be detected using this regular expression syntax:
\p{block=UpperCamelCaseBlockName}
One of the examples by the Trojan Source authors uses a Cyrillic character which can be mistaken for a Latin “H”. This can be detected using a custom rule with the regular expression:
\p{block=Cyrillic}
Note that this rule would detect all Cyrillic characters, and would only be suitable if your scanned content does and should not have any Cyrillic characters.